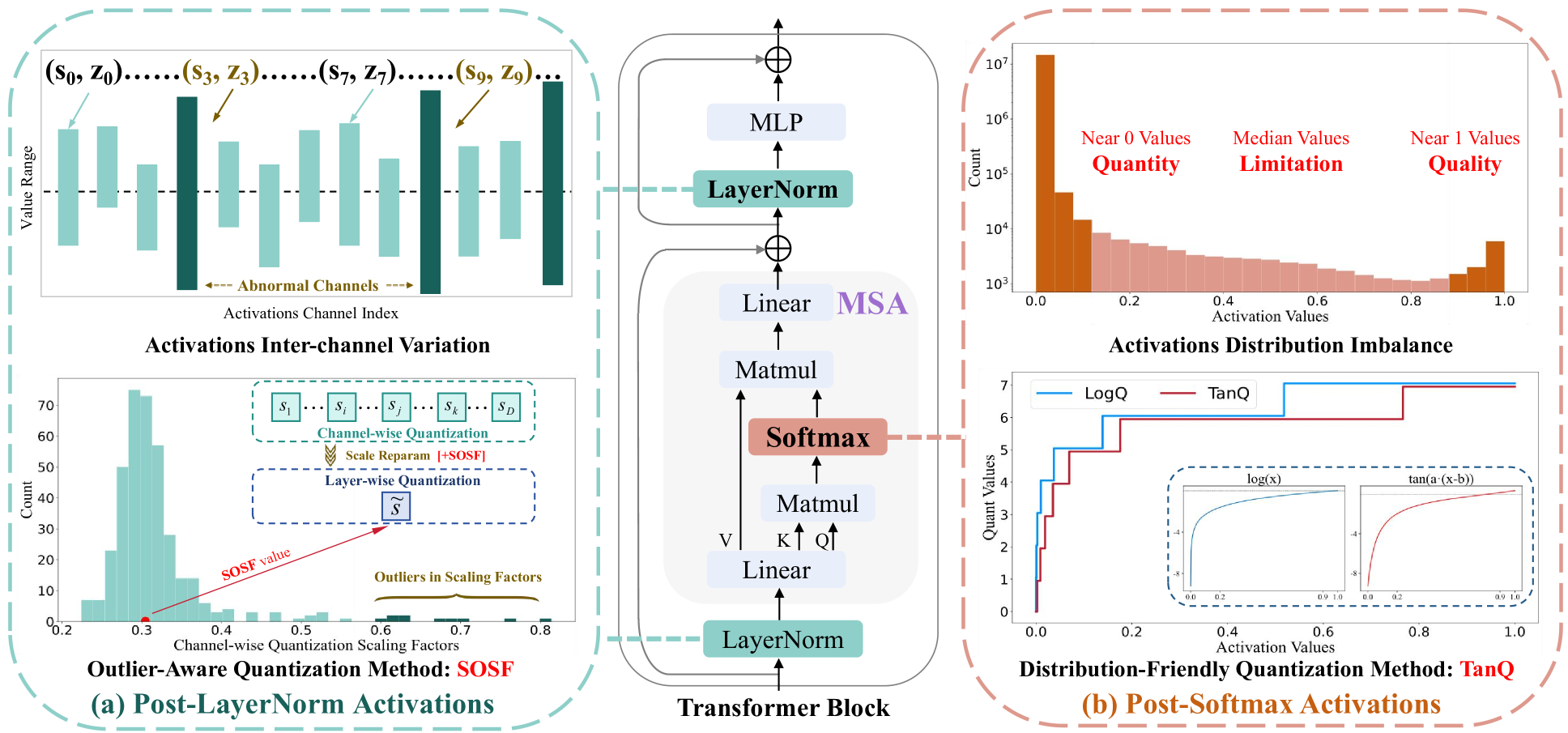
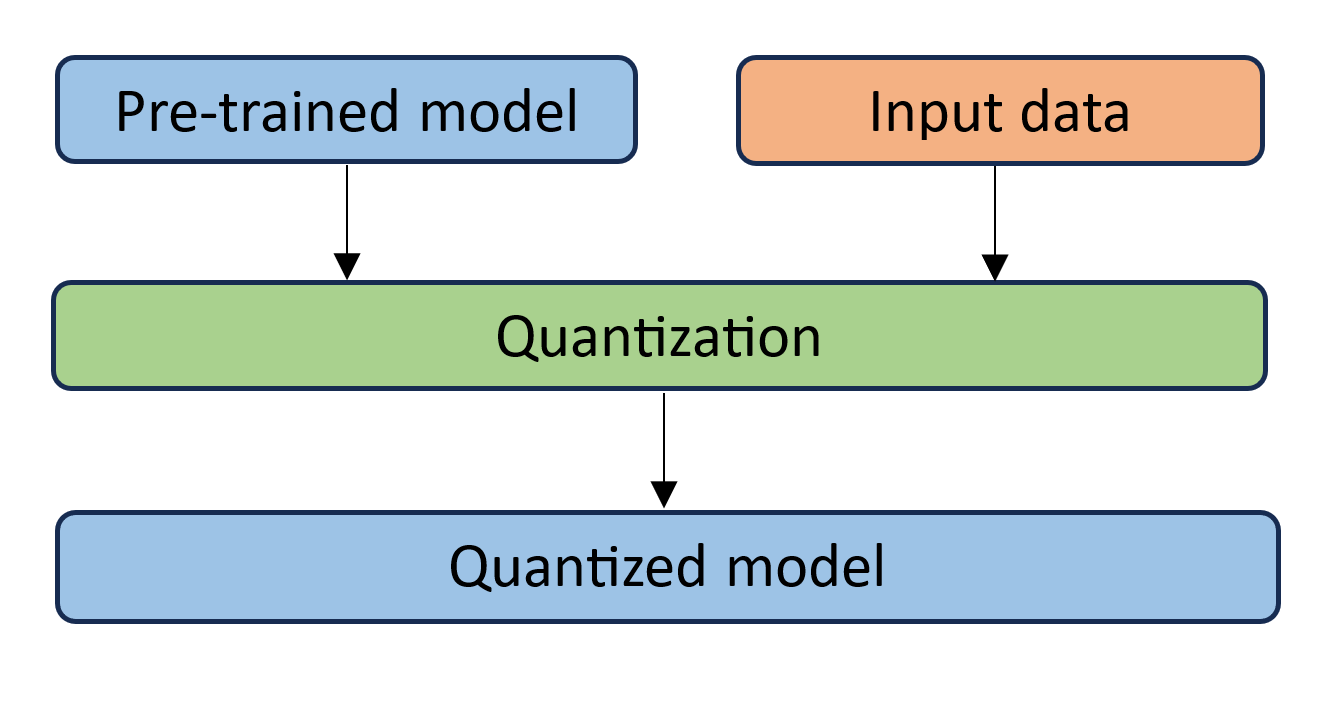
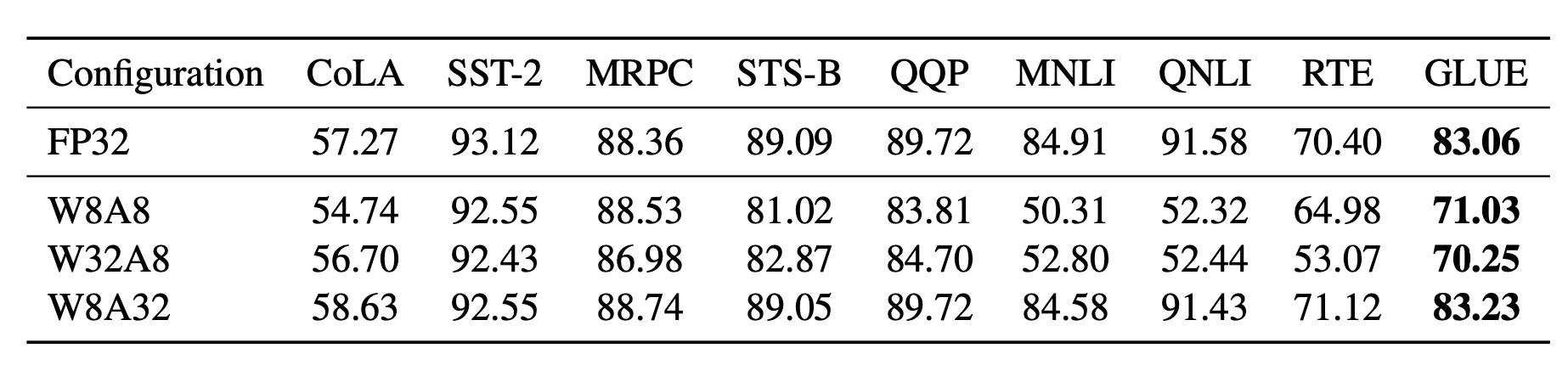
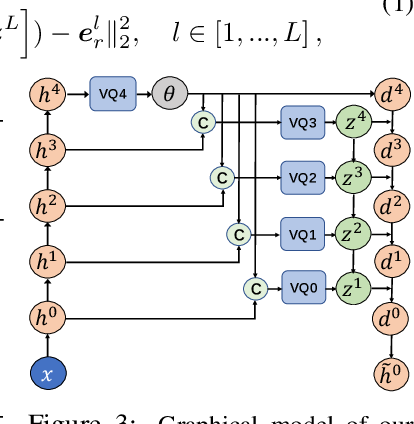
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
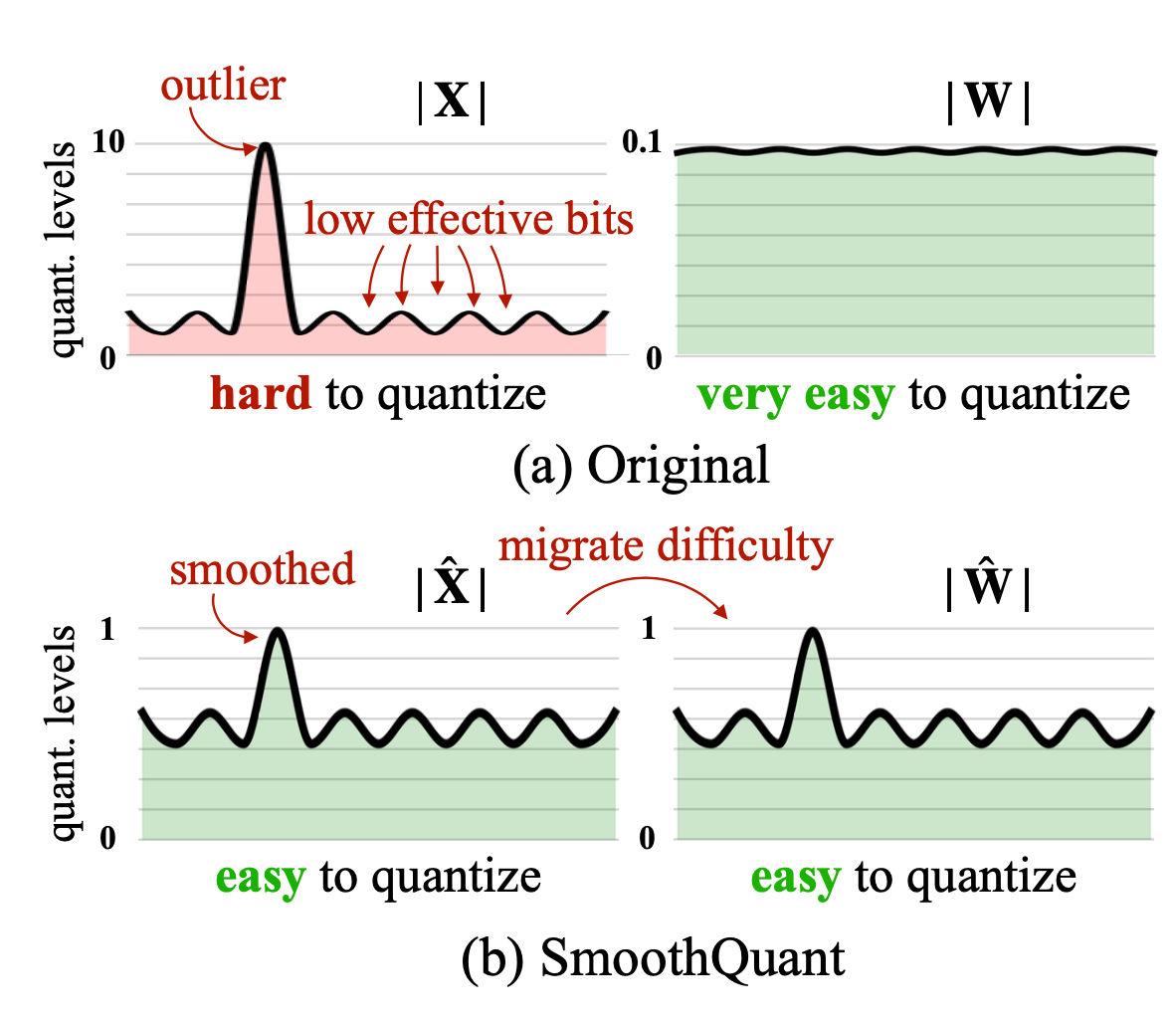
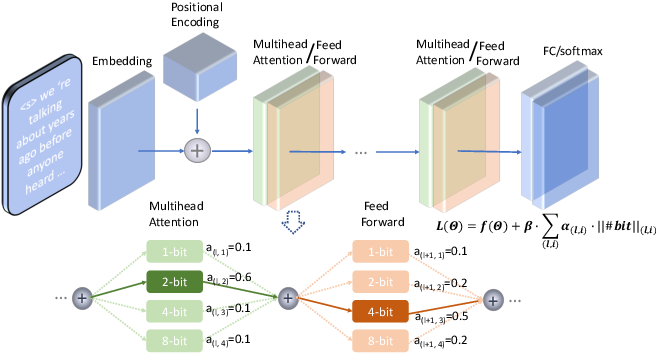
An example of mixed precision quantization of a Transformer LM using ...
Transformer Quantization at Darlene Stinson blog
Figure 2 from Mixed Precision Quantization of Transformer Language ...
Quantization of Transformer Models with Neural Compressor
Extremely Low Bit Transformer Quantization for On-Device NMT | PDF
Post-Training Quantization for Vision Transformer | DeepAI
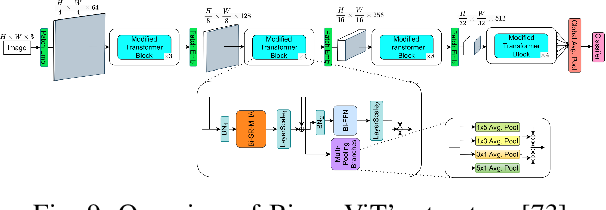
(PDF) Bi-ViT: Pushing the Limit of Vision Transformer Quantization
Mix-QViT: Mixed-Precision Vision Transformer Quantization Driven by ...
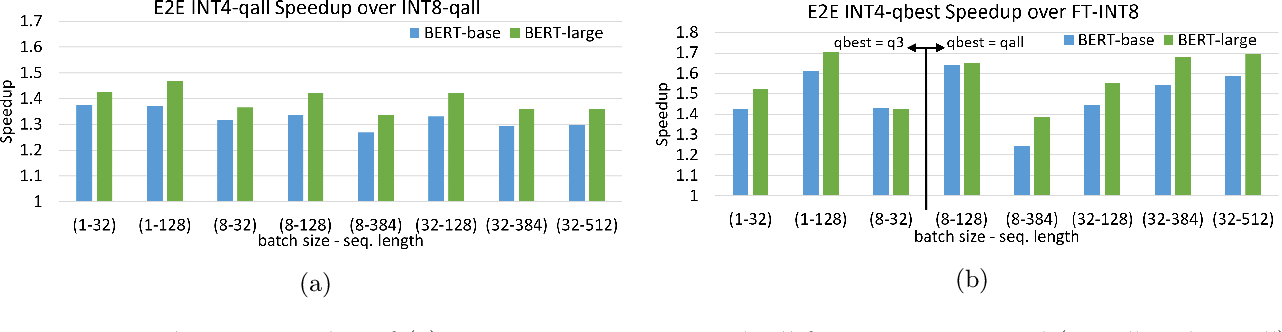
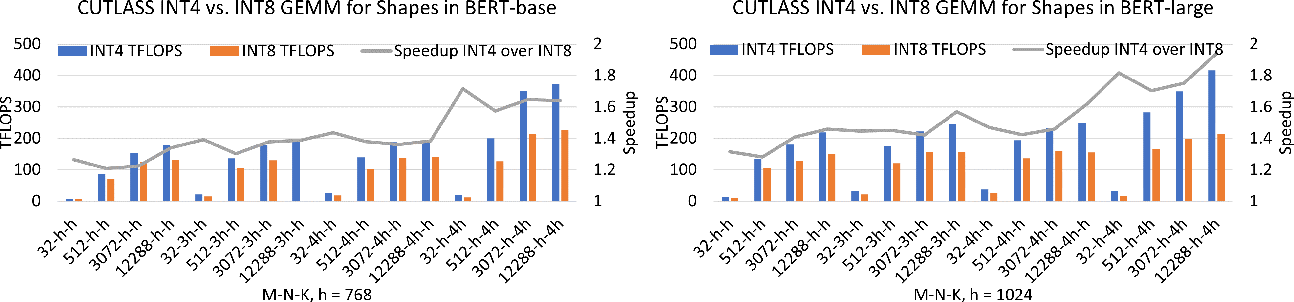
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
(PDF) Variation-aware Vision Transformer Quantization
TSPTQ-ViT: TWO-SCALED POST-TRAINING QUANTIZATION FOR VISION TRANSFORMER ...
Patch-wise Mixed-Precision Quantization of Vision Transformer | DeepAI
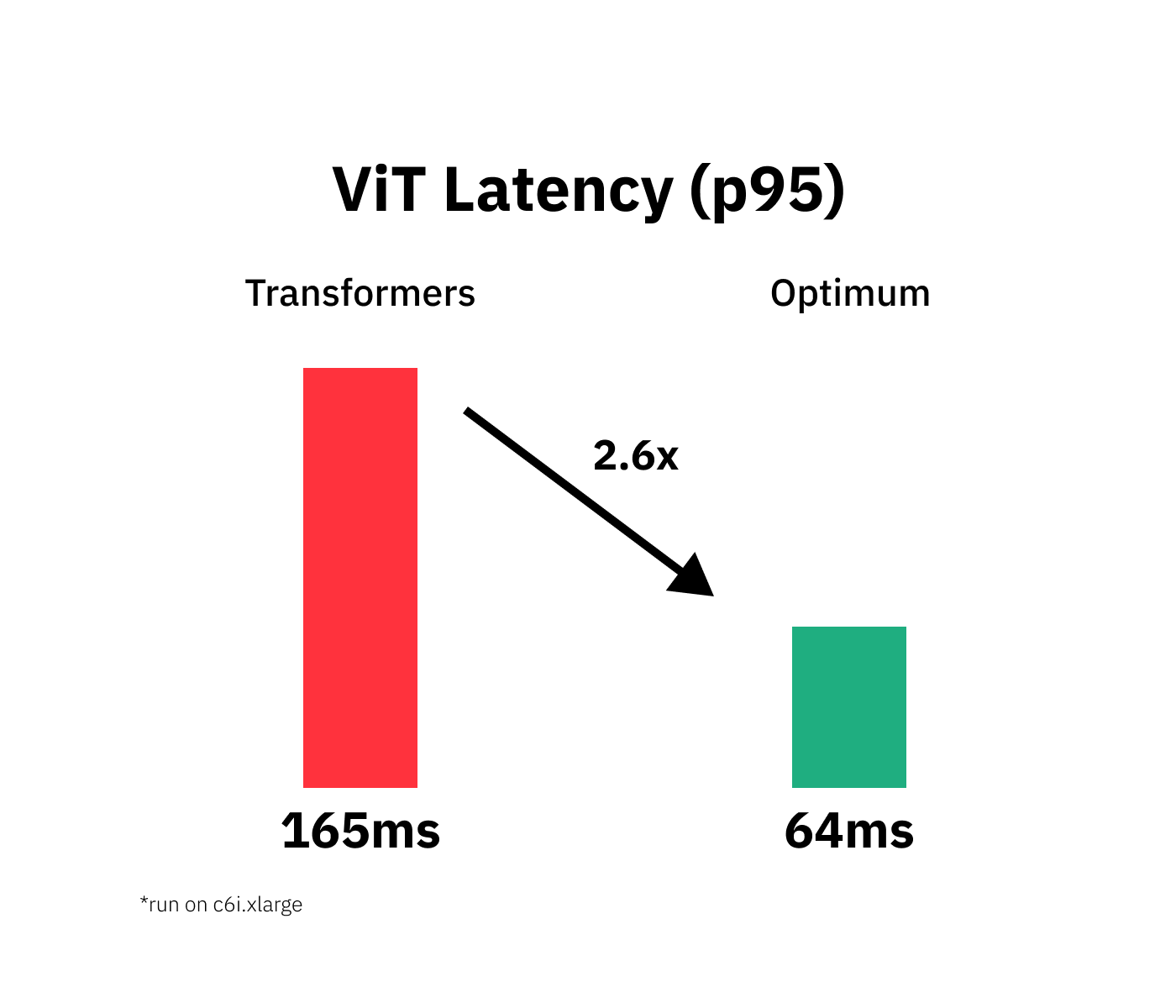
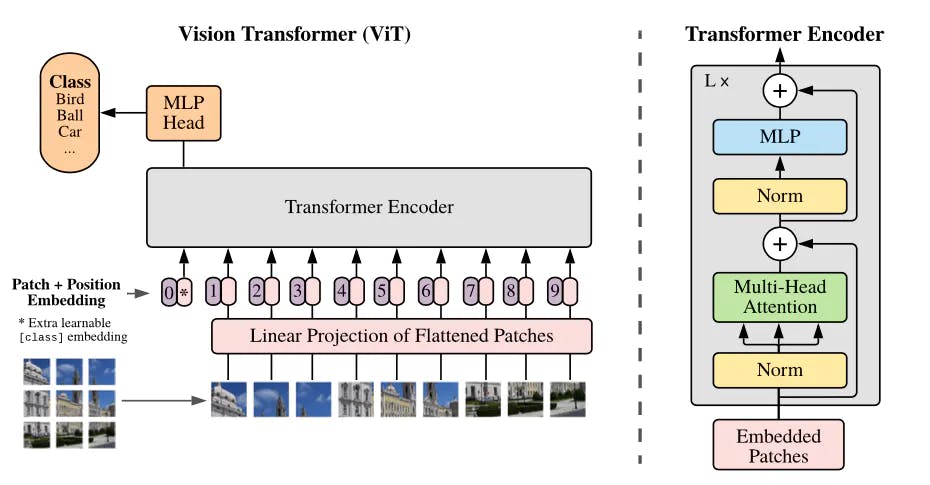
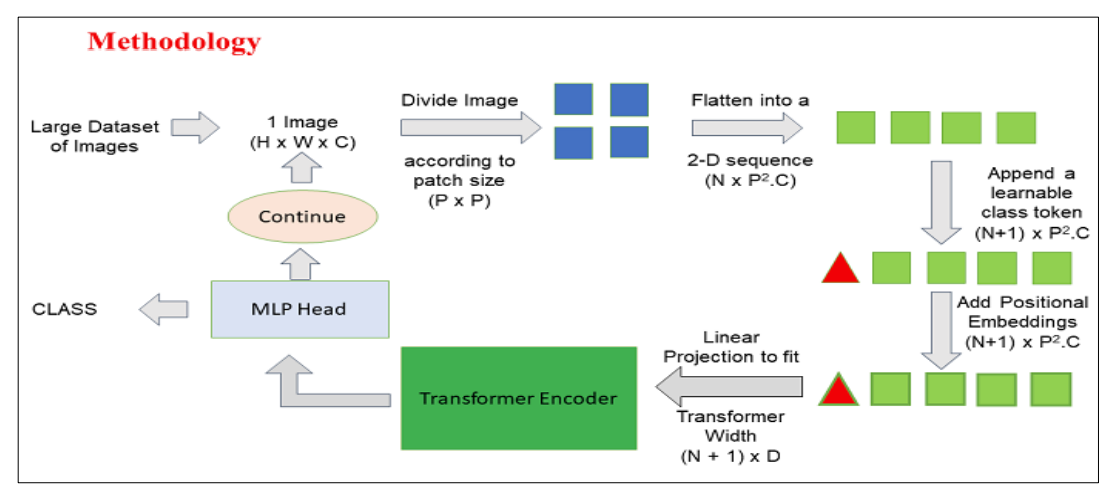
Accelerate Vision Transformer (ViT) with Quantization using Optimum
Figure 2 from Understanding INT4 Quantization for Transformer Models ...
8-bit Quantization of Transformer Model - Speaker Deck
Figure 1 from Understanding INT4 Quantization for Transformer Models ...
Quantizing your first Transformer model - Advanced Quantization ...
[论文评述] Mix-QViT: Mixed-Precision Vision Transformer Quantization Driven ...
Bi-ViT: Pushing the Limit of Vision Transformer Quantization | DeepAI
Paper page - LRP-QViT: Mixed-Precision Vision Transformer Quantization ...
Bi-ViT: Pushing the Limit of Vision Transformer Quantization | Underline
Figure 1 from Post-Training Quantization for Vision Transformer in ...
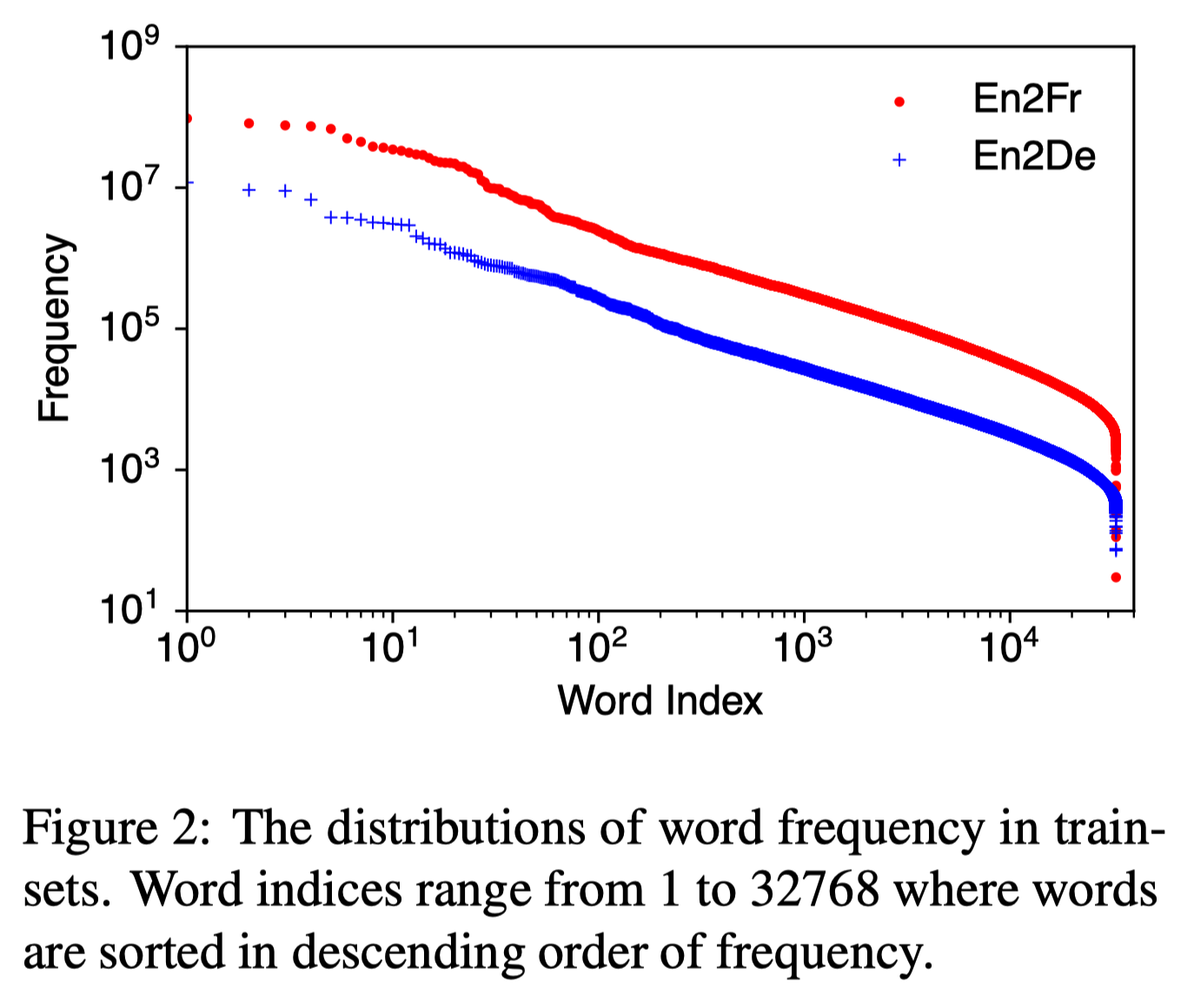
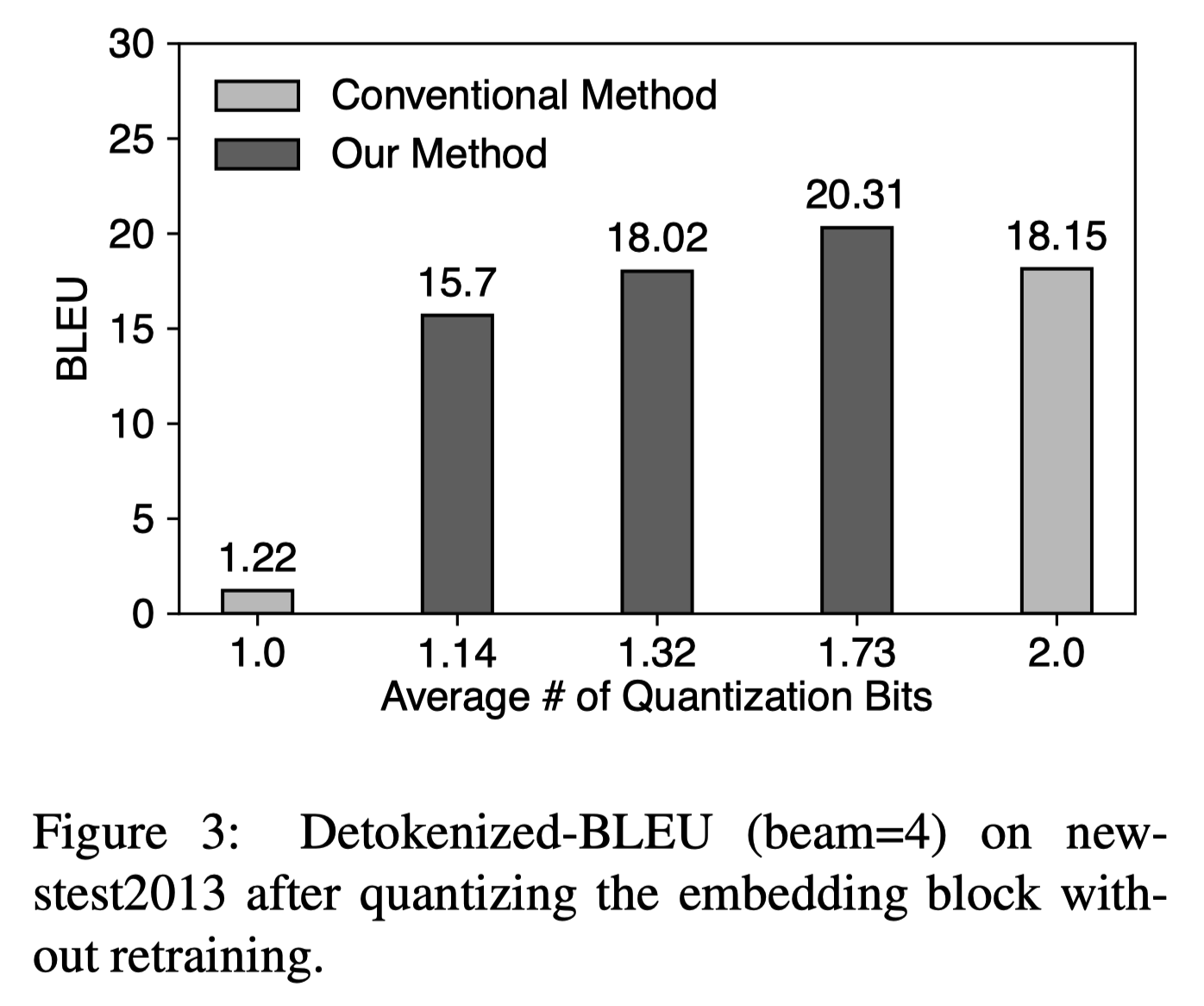
Extremely Low Bit Transformer Quantization for On-Device Neural Machine ...
[2009.07453] Extremely Low Bit Transformer Quantization for On-Device ...
PoMQ-ViT: Mixed-Precision Quantization Vision Transformer with Pareto ...
Recent Trends in Transformer Quantization | by David Cochard | ailia ...
Variation-aware Vision Transformer Quantization
Quantized General-Purpose Transformer
Fast and Accurate GPU Quantization for Transformers
VIT quantization相关论文阅读_post-training quantization for vision ...
Deciphering LLMs: From Transformers to Quantization - YouTube
Q-DiT: Accurate Post-Training Quantization for Diffusion Transformers
GenAI Inference Latency Optimization: Transformers, Quantization ...
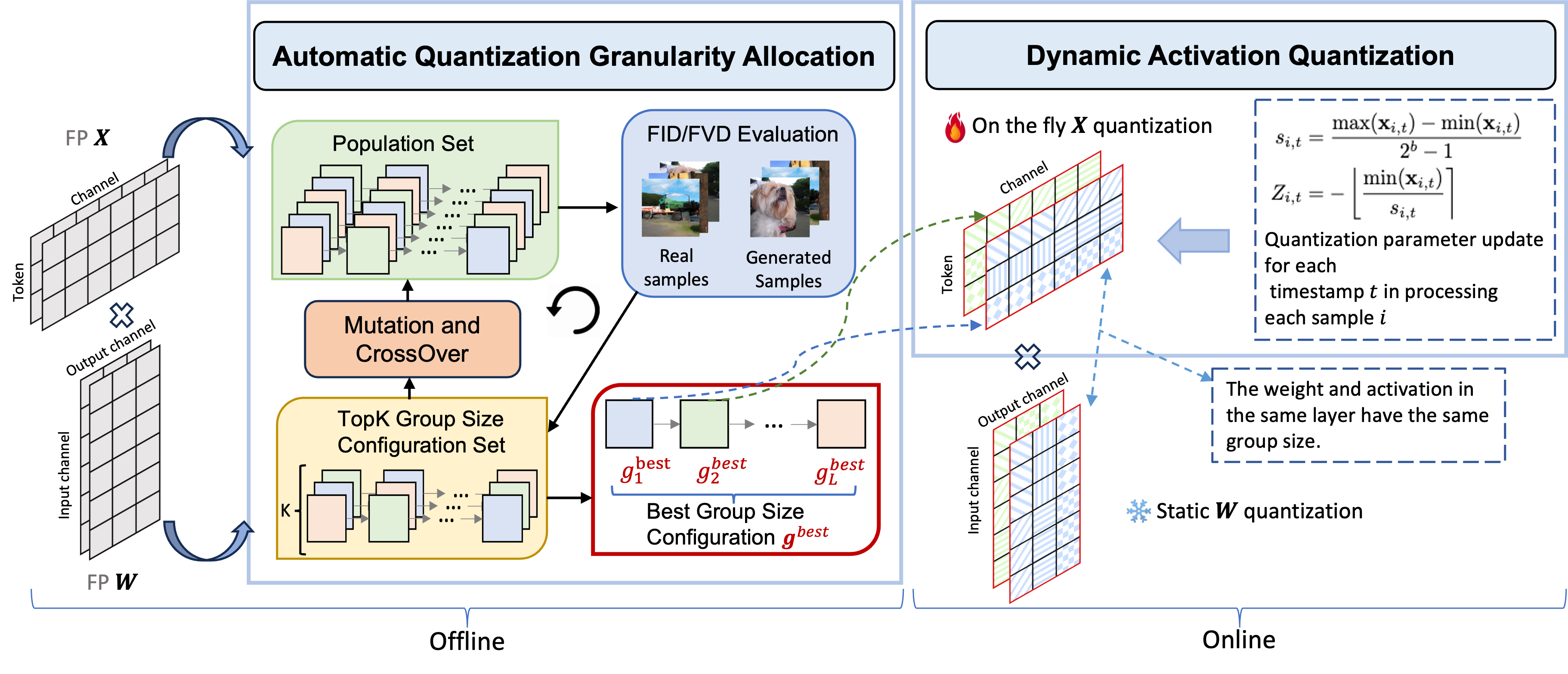
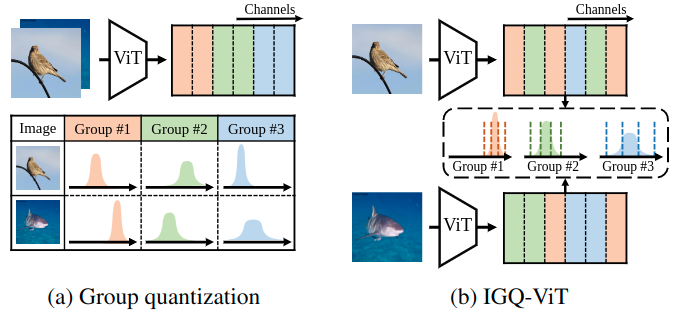
Instance-Aware Group Quantization for Vision Transformers
VQ4DiT: A Fast Post-Training Vector Quantization Method for DiTs ...
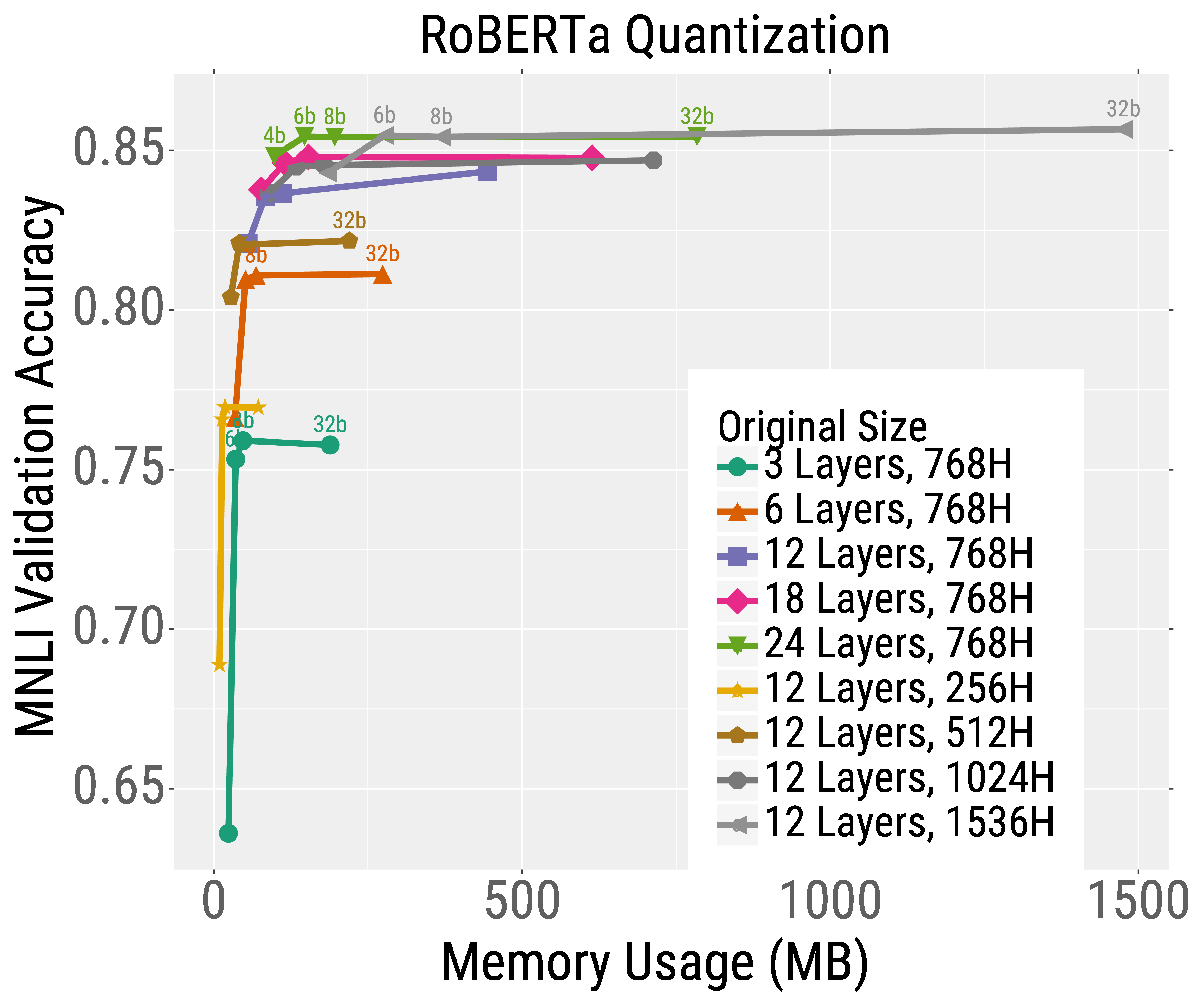
Speeding Up Transformer Training and Inference By Increasing Model Size ...
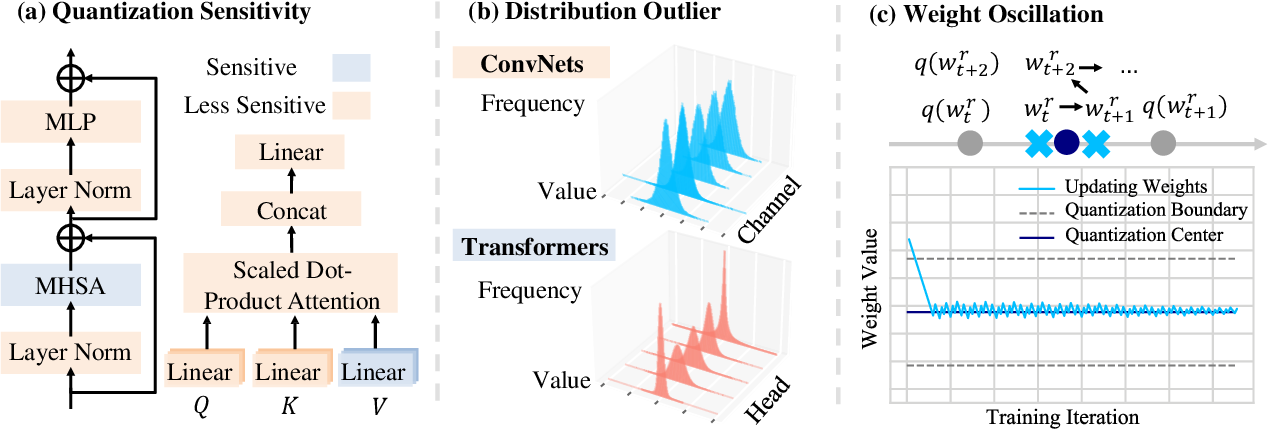
Understanding and Overcoming the Challenges of Efficient Transformer ...
Transformer-VQ Linear-Time Transformers via Vector Quantization | PDF ...
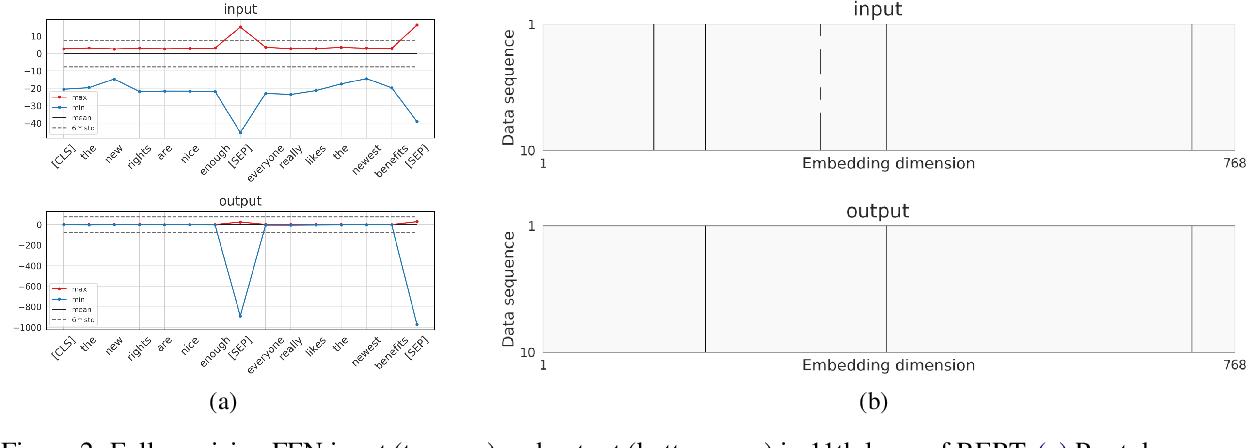
Figure 2 from Quantization Variation: A New Perspective on Training ...
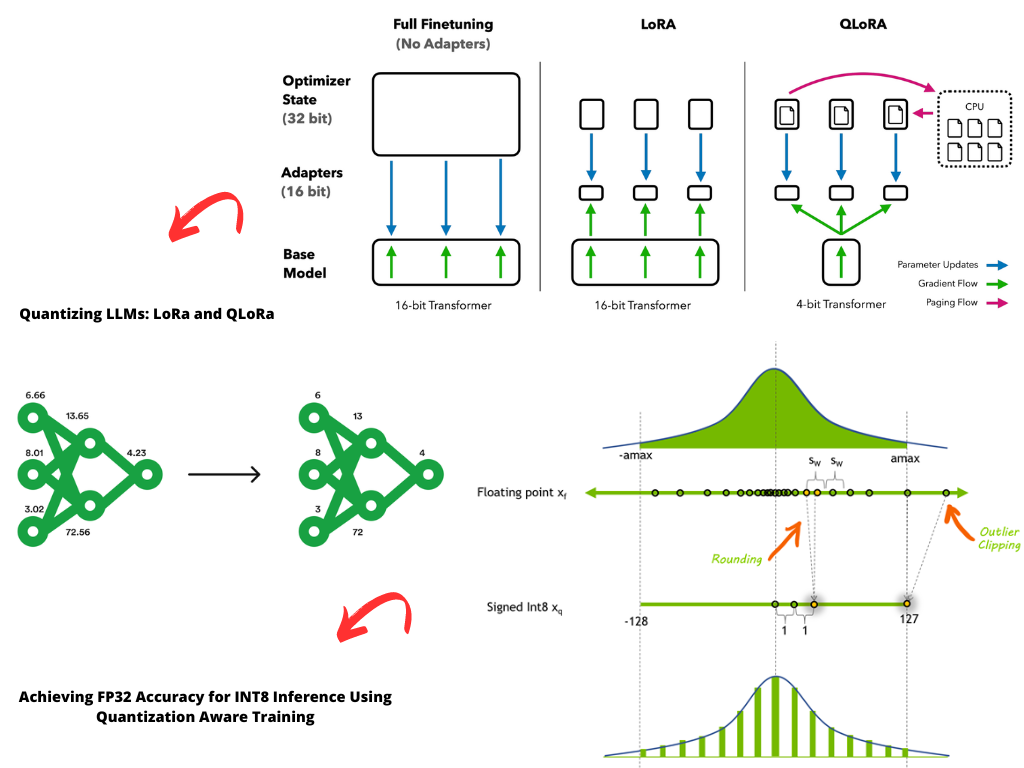
A Visual Guide to Quantization - by Maarten Grootendorst
AdaLog: Post-Training Quantization for Vision Transformers with ...
Quantization — Intel® Extension for Transformers 1.2 documentation
Figure 1 from Towards Accurate Post-Training Quantization for Vision ...
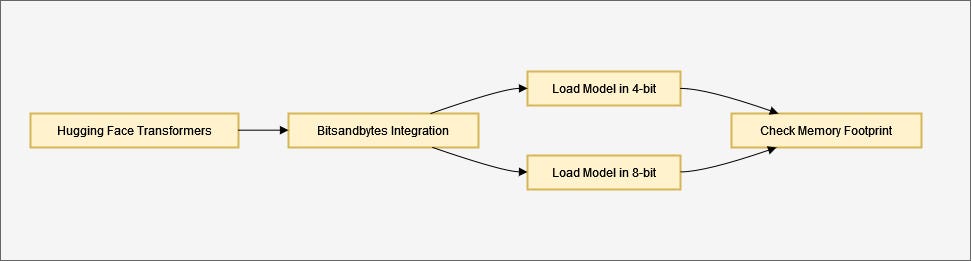
LLM Quantization with Hugging Face Transformers
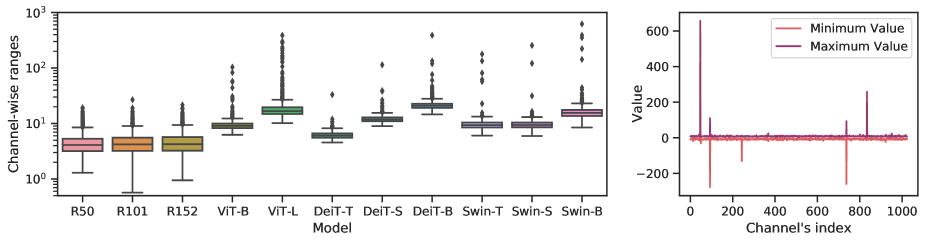
PTQ4ViT: Post-Training Quantization for Vision Transformers with Twin ...
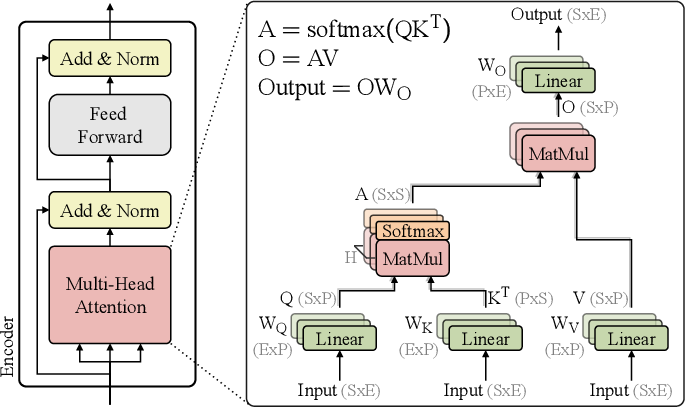
Large Transformer Model Inference Optimization | Lil'Log
VQ4DiT: Efficient Post-Training Vector Quantization for Diffusion ...
Selectq Calibration Data Selection For Post-Training Quantization at ...
(PDF) TSPTQ-ViT: Two-scaled post-training quantization for vision ...
Hierarchical Vector Quantized Transformer for Multi-class Unsupervised ...
How Quantization and Pruning Actually Work | by Zaina Haider | Nov ...
[2111.13824] FQ-ViT: Post-Training Quantization for Fully Quantized ...
[ICLR 25] ViDiT-Q: Efficient and Accurate Quantization of Diffusion ...
[2111.12293] PTQ4ViT: Post-Training Quantization for Vision ...
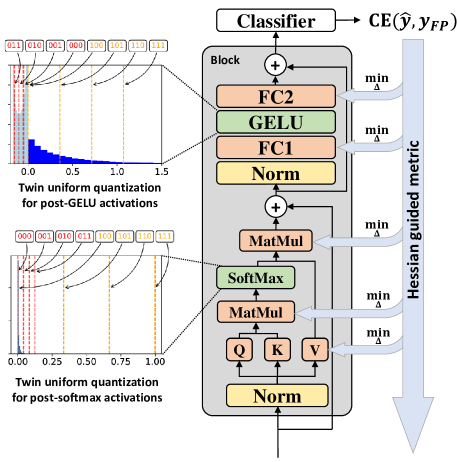
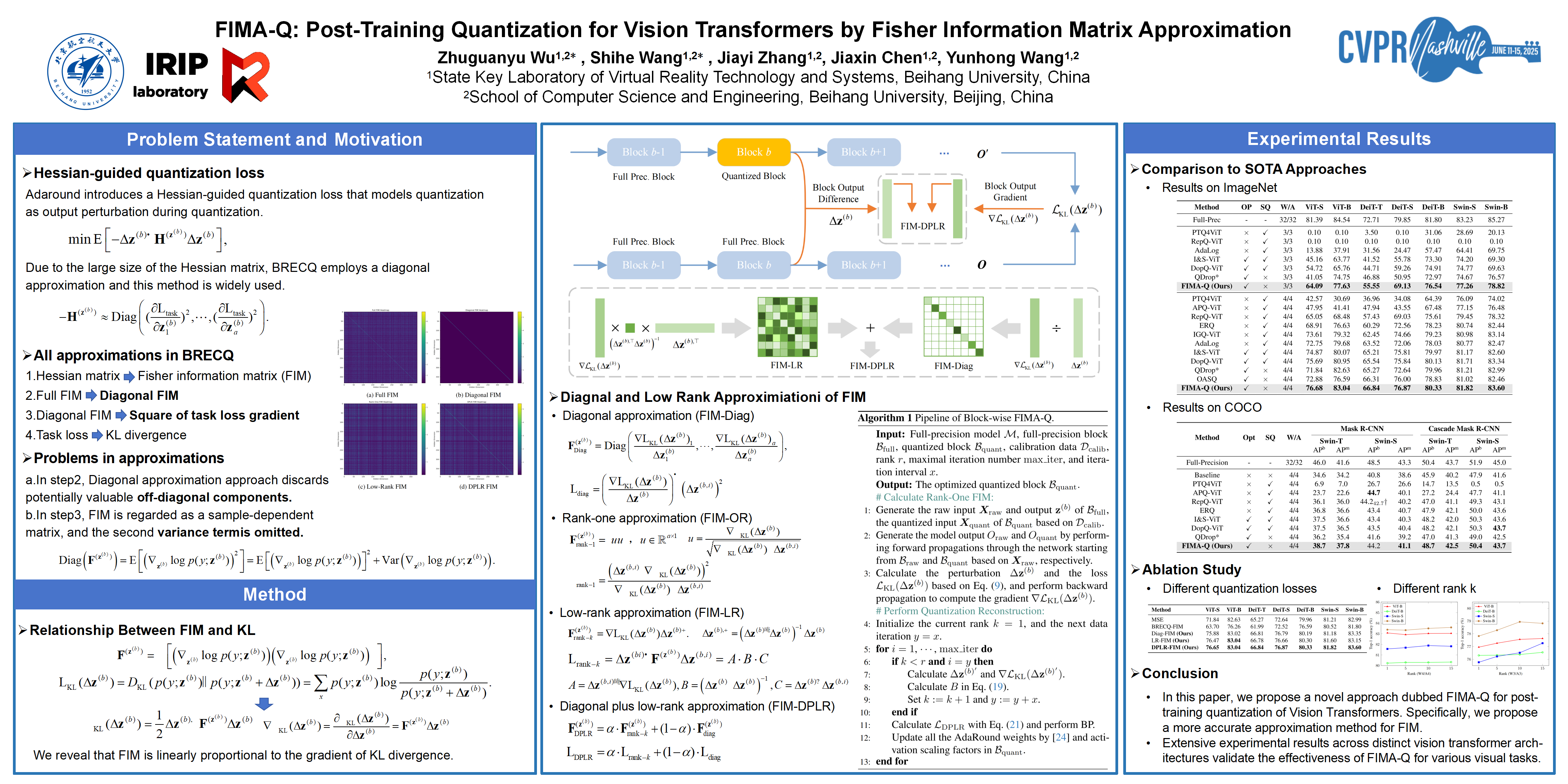
CVPR Poster FIMA-Q: Post-Training Quantization for Vision Transformers ...
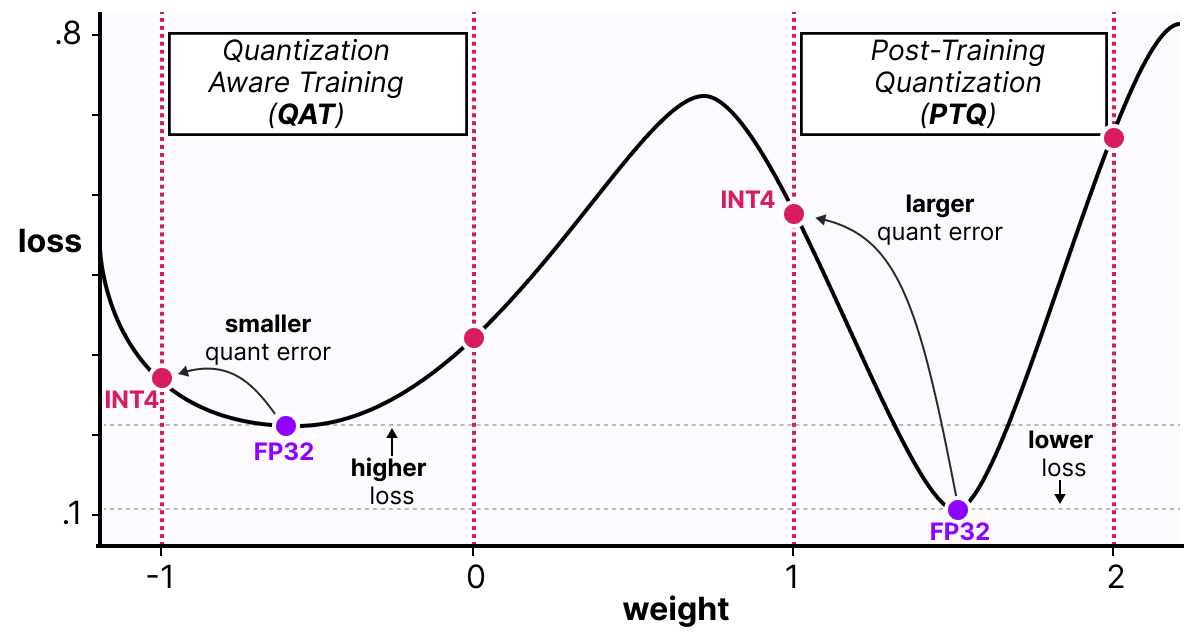
Quantization Aware Training (QAT) vs. Post-Training Quantization (PTQ ...
Understanding and Improving Knowledge Distillation for Quantization ...
FQ-ViT: Post-Training Quantization for Fully Quantized Vision ...
[论文评述] P$^2$-ViT: Power-of-Two Post-Training Quantization and ...
Transformer-VQ: Linear-Time Transformers with Vector Quantization ...
(PDF) Q-DiT: Accurate Post-Training Quantization for Diffusion Transformers
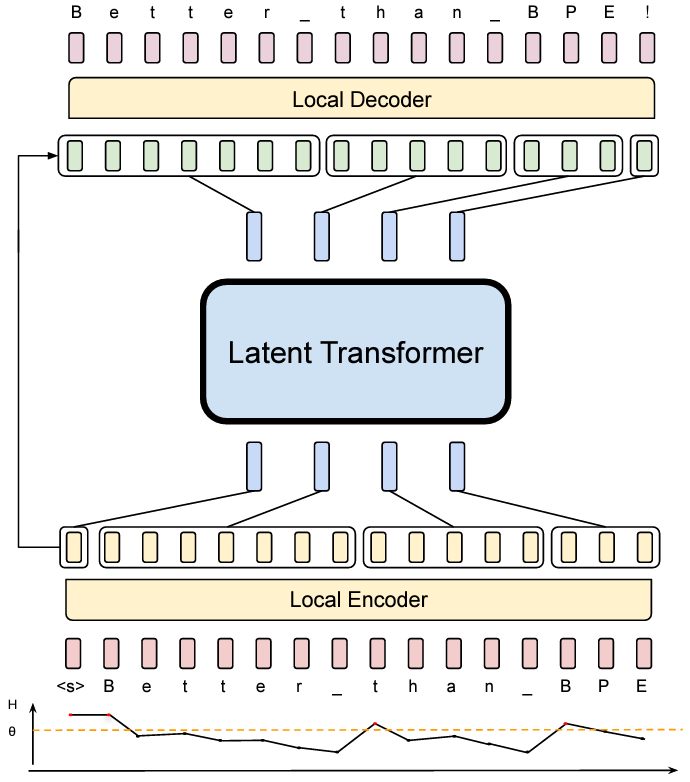
Improving Semantic Control in Discrete Latent Spaces with Transformer ...
(PDF) Q-DETR: An Efficient Low-Bit Quantized Detection Transformer
【量化】Post-Training Quantization for Vision Transformer-CSDN博客
Figure 9 from Model Quantization and Hardware Acceleration for Vision ...
Transformer-VQ: Linear-Time Transformers via Vector Quantization
Understanding Activation-Aware Weight Quantization (AWQ): Boosting ...
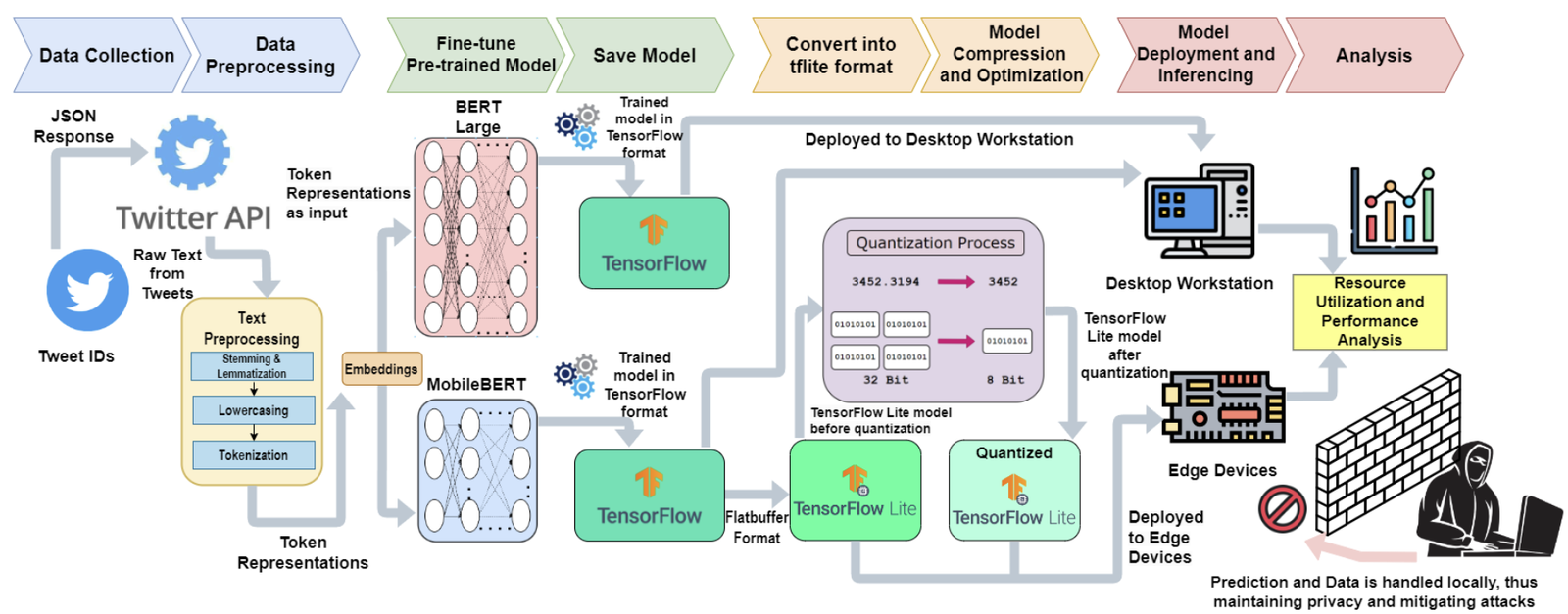
Quantized Transformer Language Model Implementations on Edge Devices ...
(PDF) GPTQ: Accurate Post-Training Quantization for Generative Pre ...
Figure 2 from Understanding and Overcoming the Challenges of Efficient ...
大模型入门指南 - Quantization:小白也能看懂的“模型量化”全解析_大模型量化-CSDN博客
Making LLMs lighter with AutoGPTQ and transformers
大模型量化感知训练 LLM-QAT_quantization aware training-CSDN博客
模型量化(Model Quantization)-CSDN博客
GitHub - Qualcomm-AI-research/transformer-quantization
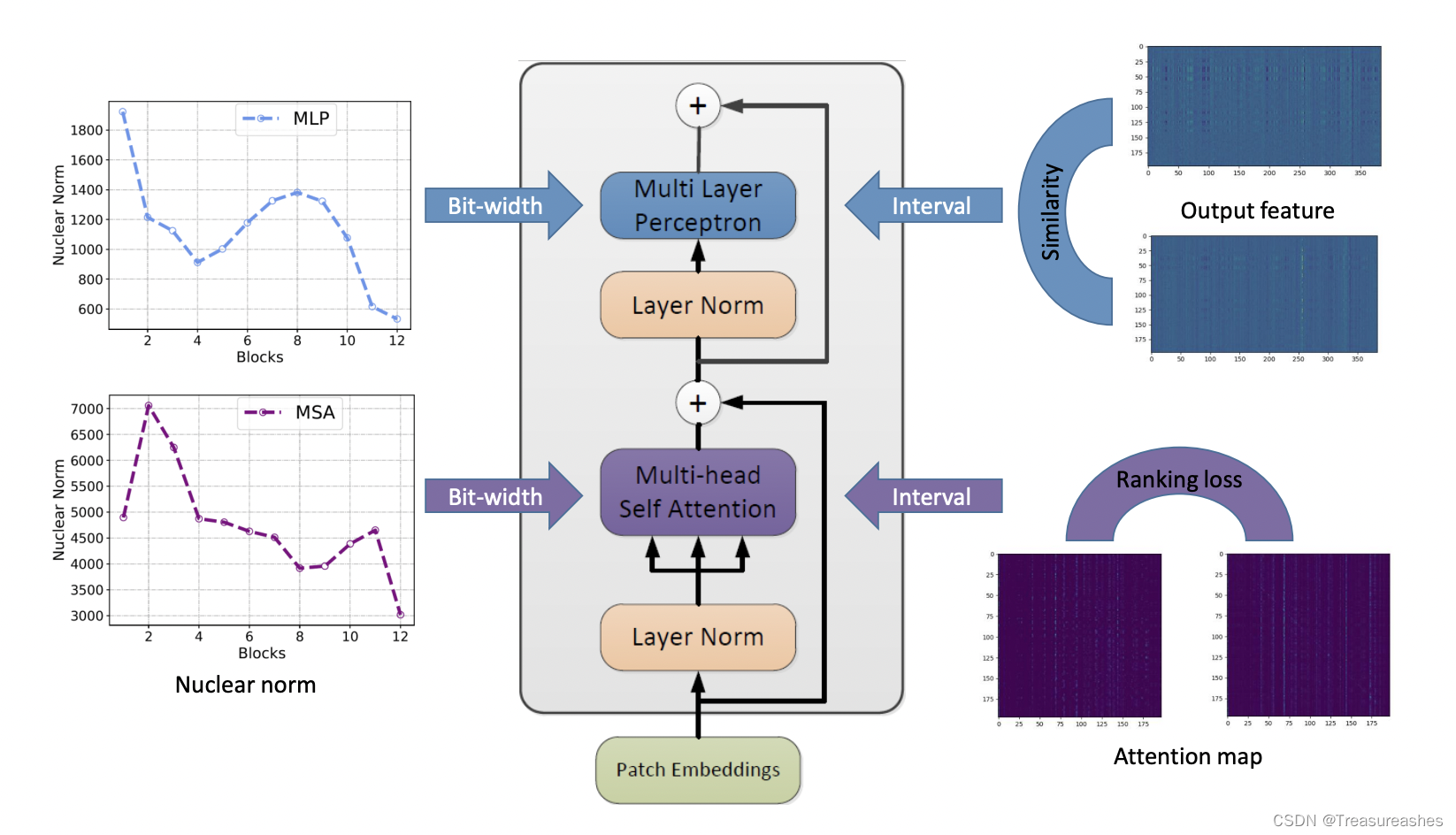
基于层重要性和量化敏感度的视觉Transformer混合精度量化 Mix-QViT: Mixed-Precision Vision ...
GitHub - Alexstrasza98/Transformer-Quantization: The final project ...
SwiftTron: An Efficient Hardware Accelerator for Quantized Transformers ...
Figure 1 from ITA: An Energy-Efficient Attention and Softmax ...
Figure 3 from VQ-DcTr: Vector-Quantized Autoencoder With Dual-channel ...
(PDF) Understanding and Overcoming the Challenges of Efficient ...
Paper page - Transformer-VQ: Linear-Time Transformers via Vector ...
Quantizing Vision Transformers for Efficient Deployment: Strategies and ...
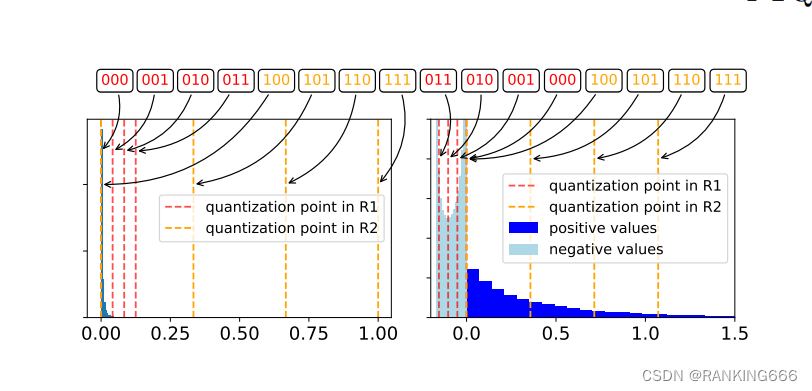
Figure 3 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
[2310.17723] ZeroQuant-HERO: Hardware-Enhanced Robust Optimized Post ...
(PDF) Quantization-Aware and Tensor-Compressed Training of Transformers ...
Understanding Quantization: Optimizing AI Models for Efficiency | by ...
TransSMPL: Efficient Human Pose Estimation with Pruned and Quantized ...
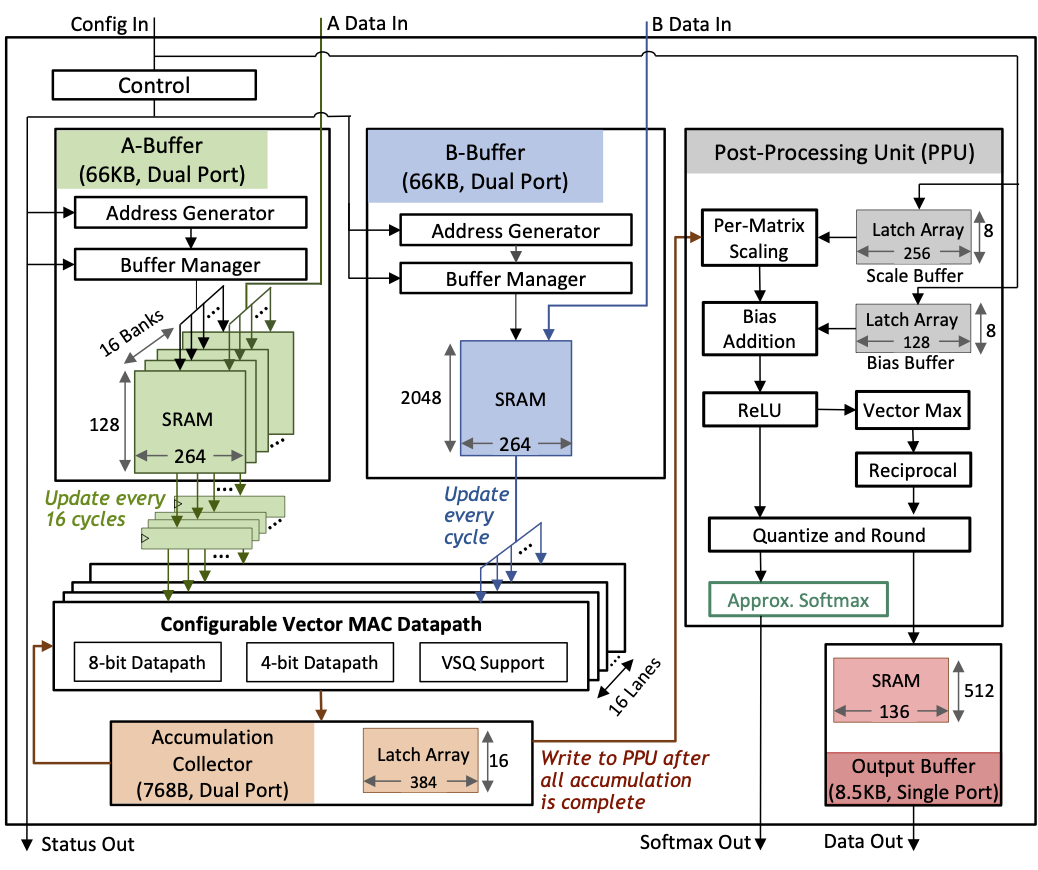
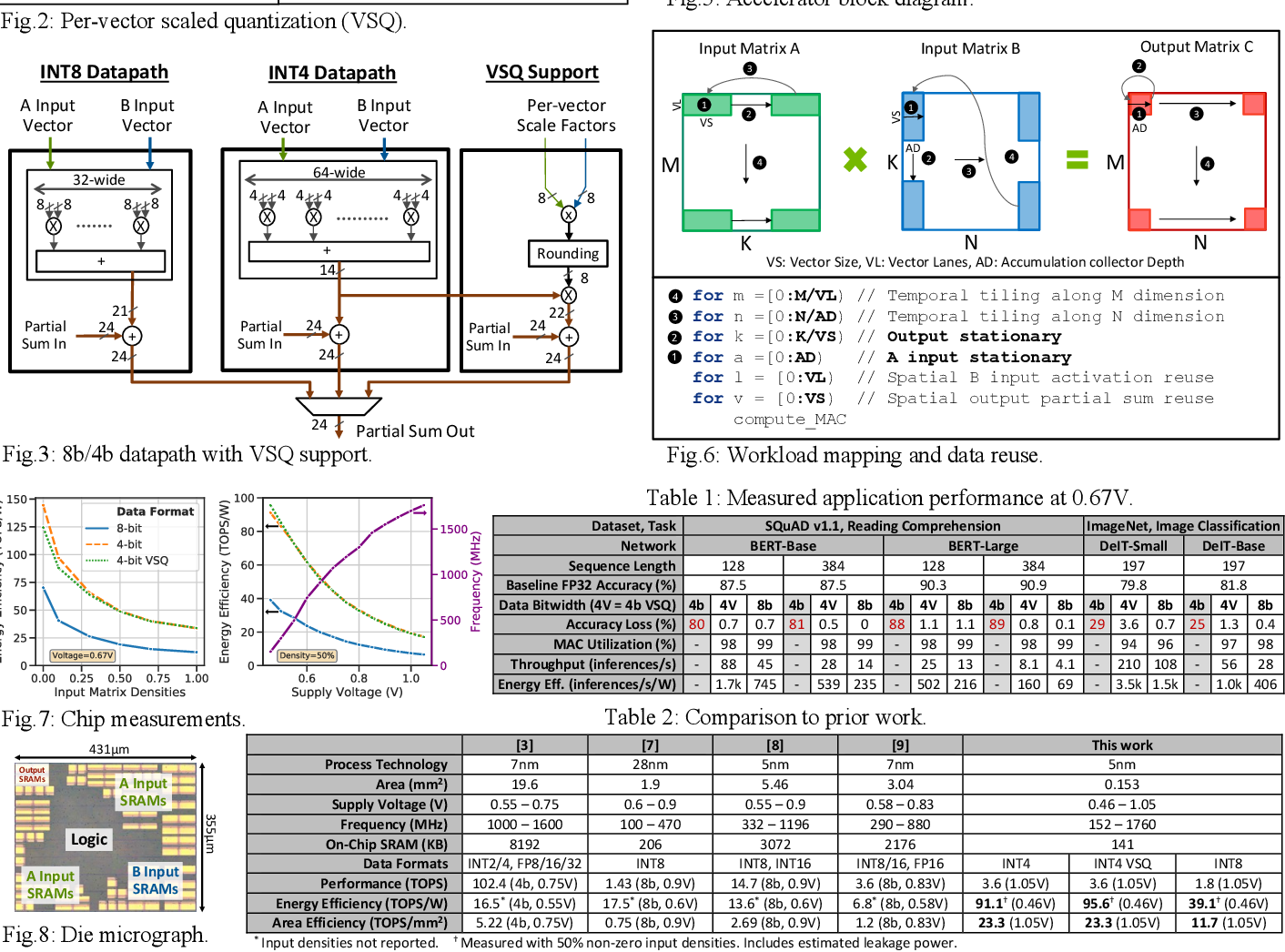
Table 2 from A 17–95.6 TOPS/W Deep Learning Inference Accelerator with ...
Figure 7 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
Optimizing LLMs for Performance and Accuracy with Post-Training ...